
Creating a tator-py AWS Lambda Layer
To use python packages that are not included in the AWS Lambda runtime, you must create a Layer.
This post explains what AWS Lambda is and outlines how to create a Layer containing tator-py and
add it to your Lambda.
What is AWS Lambda?
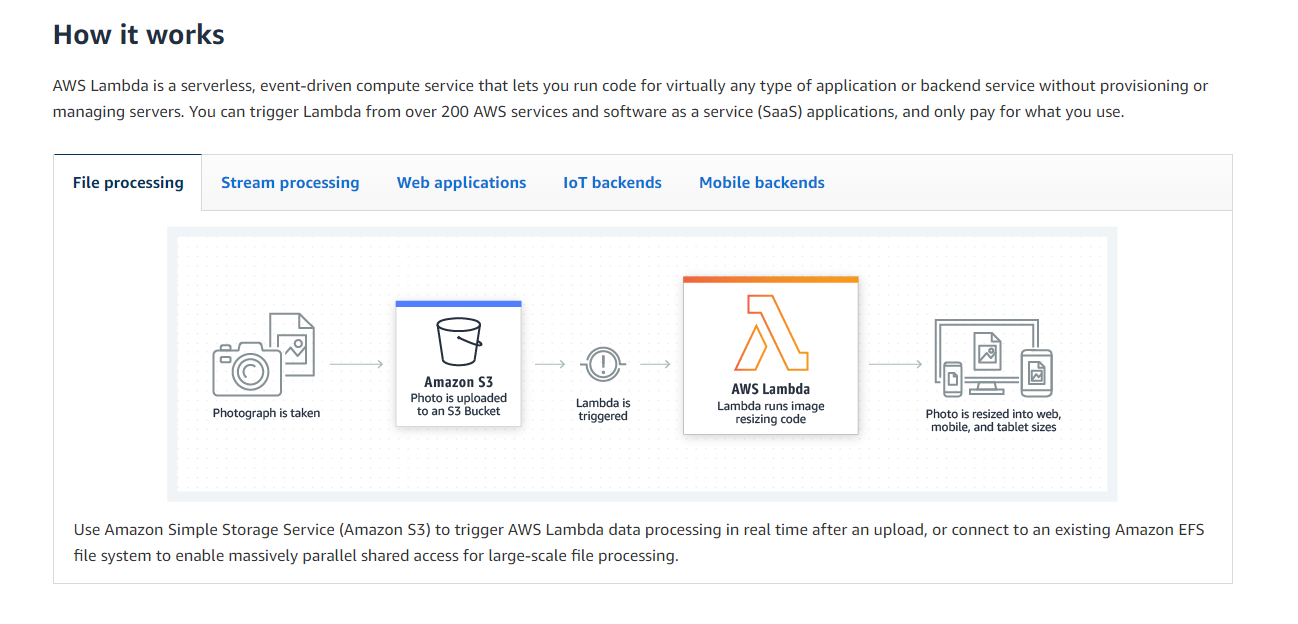
AWS Lambda is an event-driven compute service. It allows you to execute a script in response to events occurring in other AWS resources, such as S3. The configuration of these event responses are called Triggers. The script is given details about the event(s) triggering it as an input, allowing it to use this information to perform its task.
What is a Lambda Layer
It is possible your script requires a dependency that is not in the environment provided by AWS. To add one or more dependencies to the environment, a Layer containing the dependencies can be supplied. This can be an existing Layer provided by AWS or a custom one created by a user. Once identified or created, the layer is added to an existing Lambda function, which allows the use of any dependencies installed in the layer by the code in the Lambda function.
Why use a Lambda function
Some of our customers have existing workflows that upload media to S3 that need to be imported into a project in Tator. This requires an intermediate step, which could be manual or automated, and AWS Lambda provides a convenient S3 PUT event trigger that allows the Lambda to run on new uploads to a bucket (and it can even filter by prefix). This is also better than a standalone automated approach because it is only using resources while it is active and it does not need to poll the bucket for the appearance of new objects.
Create the tator-py zip archive
First, create a temporary folder to work in, containing a directory named python:
~$ mkdir -p tator-py-layer/python
~$ cd tator-py-layer
The zip archive we create must have a python folder at its root, otherwise Lambda will not be able
to find the installed packages.
Next, install tator-py in the python directory:
tator-py-layer$ pip3 install --target ./python/ tator
This will also install all required dependencies for tator-py. Finally, create the zip archive
that will define the Layer and remove the temporary directory:
tator-py-layer$ zip -r ../tator-py.zip .
tator-py-layer$ cd ../
~$ rm -rf tator-py-layer
Be sure that the version of Python being used to install tator-py to the target directory is
compatible with the runtime version specified in AWS Lambda
Upload the tator-py zip archive
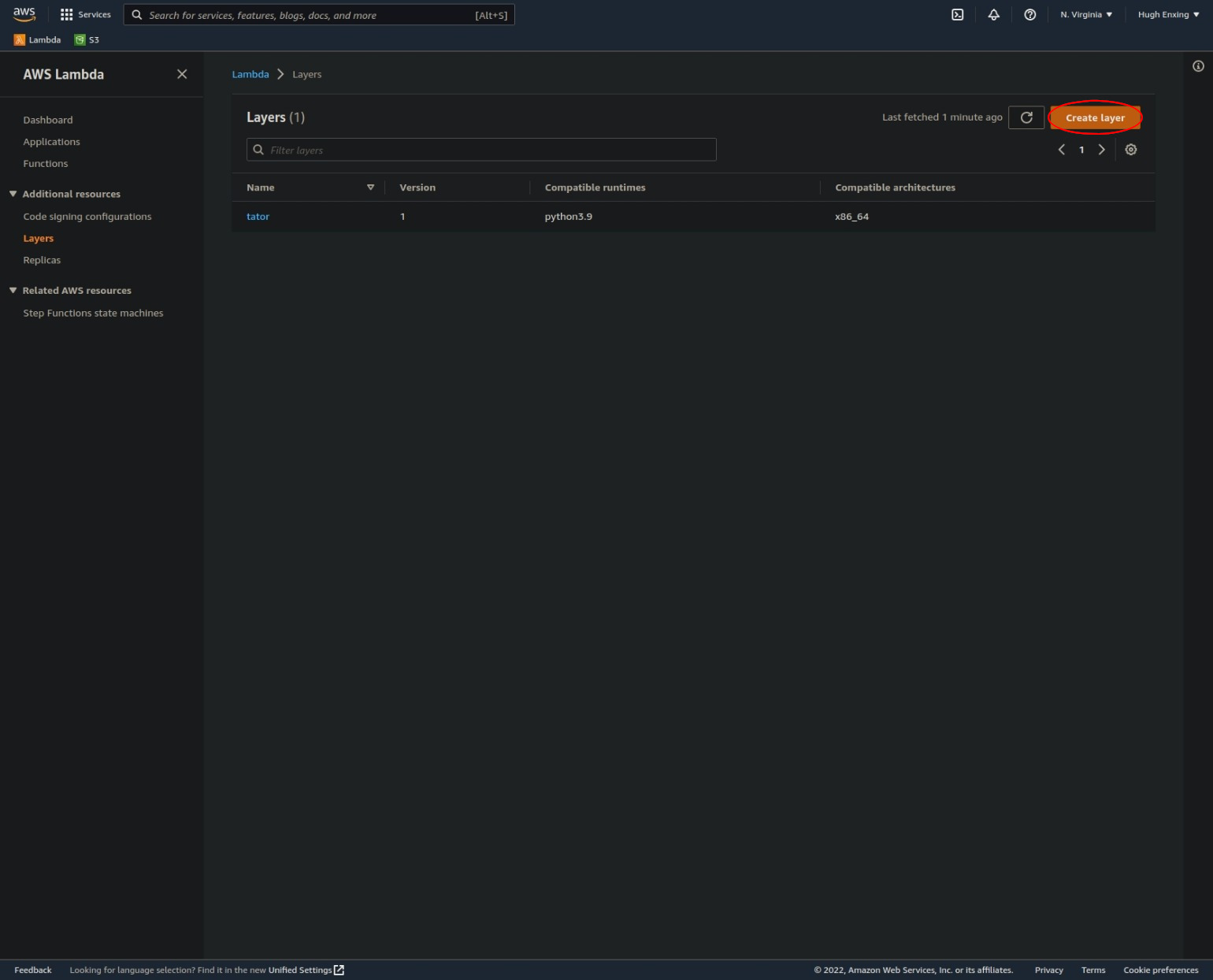
Navigate to the AWS Lambda Layers page (taking care to select the desired region) and click the "Create layer" button:
Give your layer a name, upload the zip archive created in the last step, and, optionally, add a description, choose compatible architectures, and choose compatible runtimes.
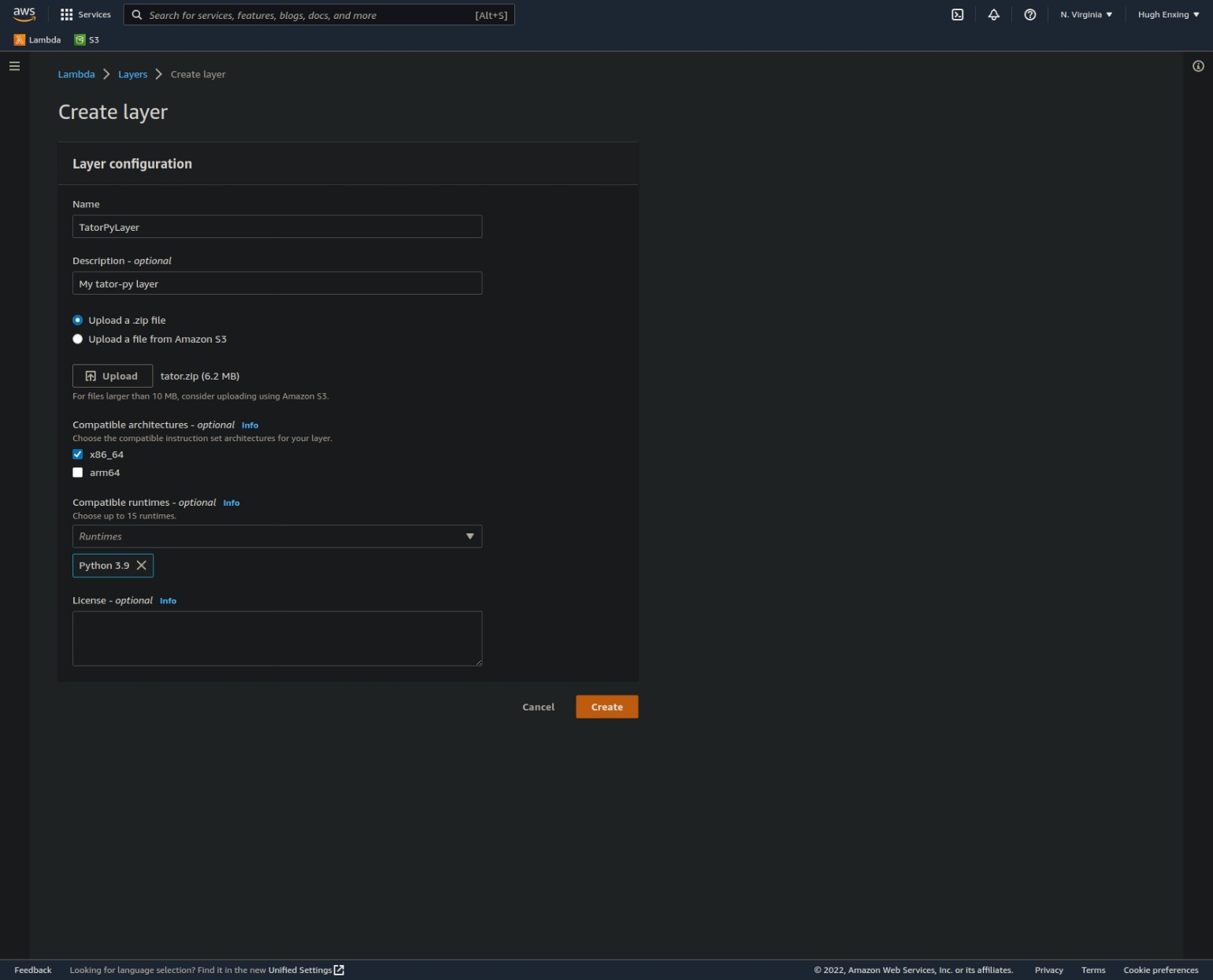
Finally, click the "Create" button.
Add the layer to a Lambda function
On an existing Lambda function, scroll to the bottom of the "code" tab and click the "Add a layer" button:
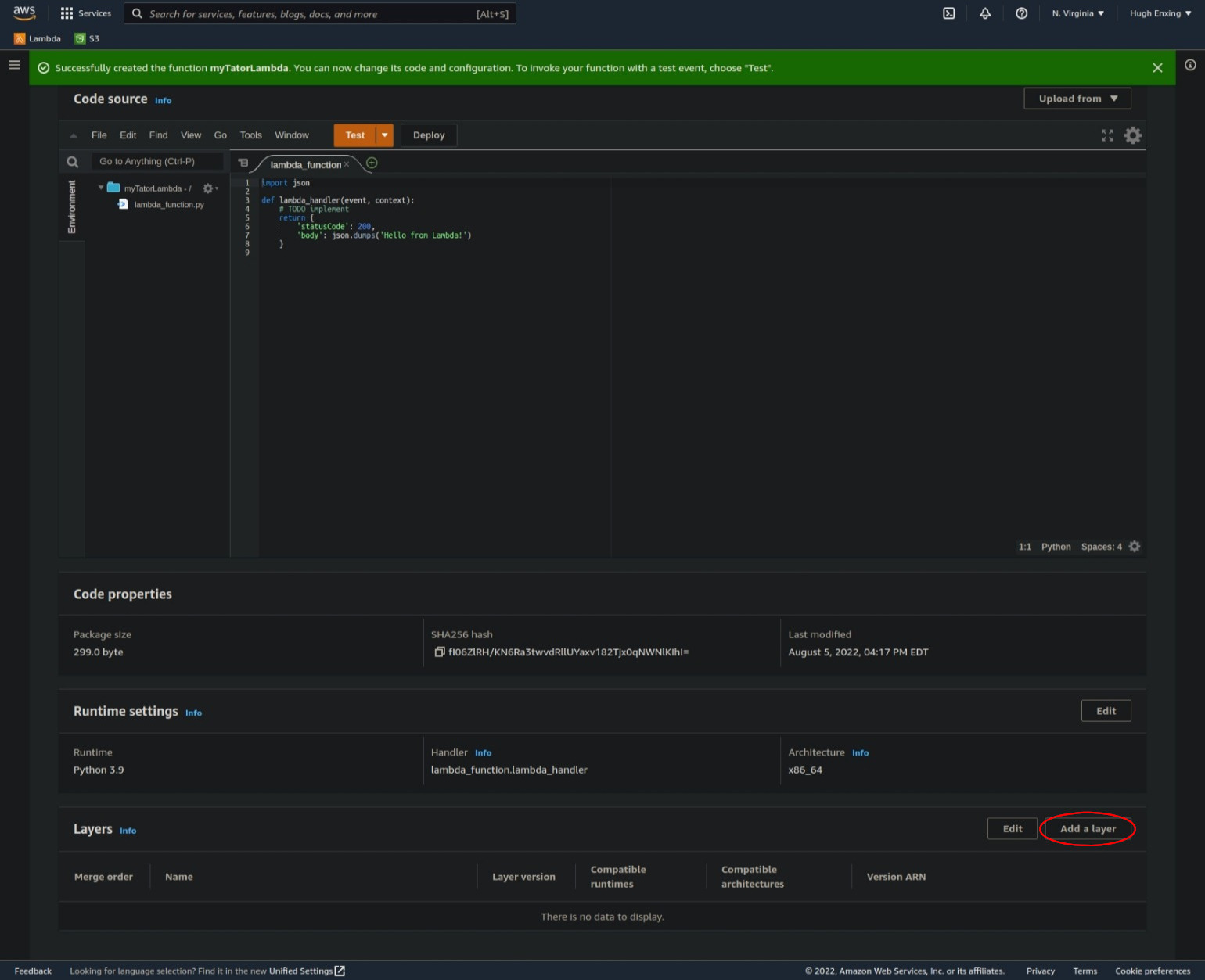
Select the "Custom layers" option, then from the drop-down, choose the layer created in the last step:
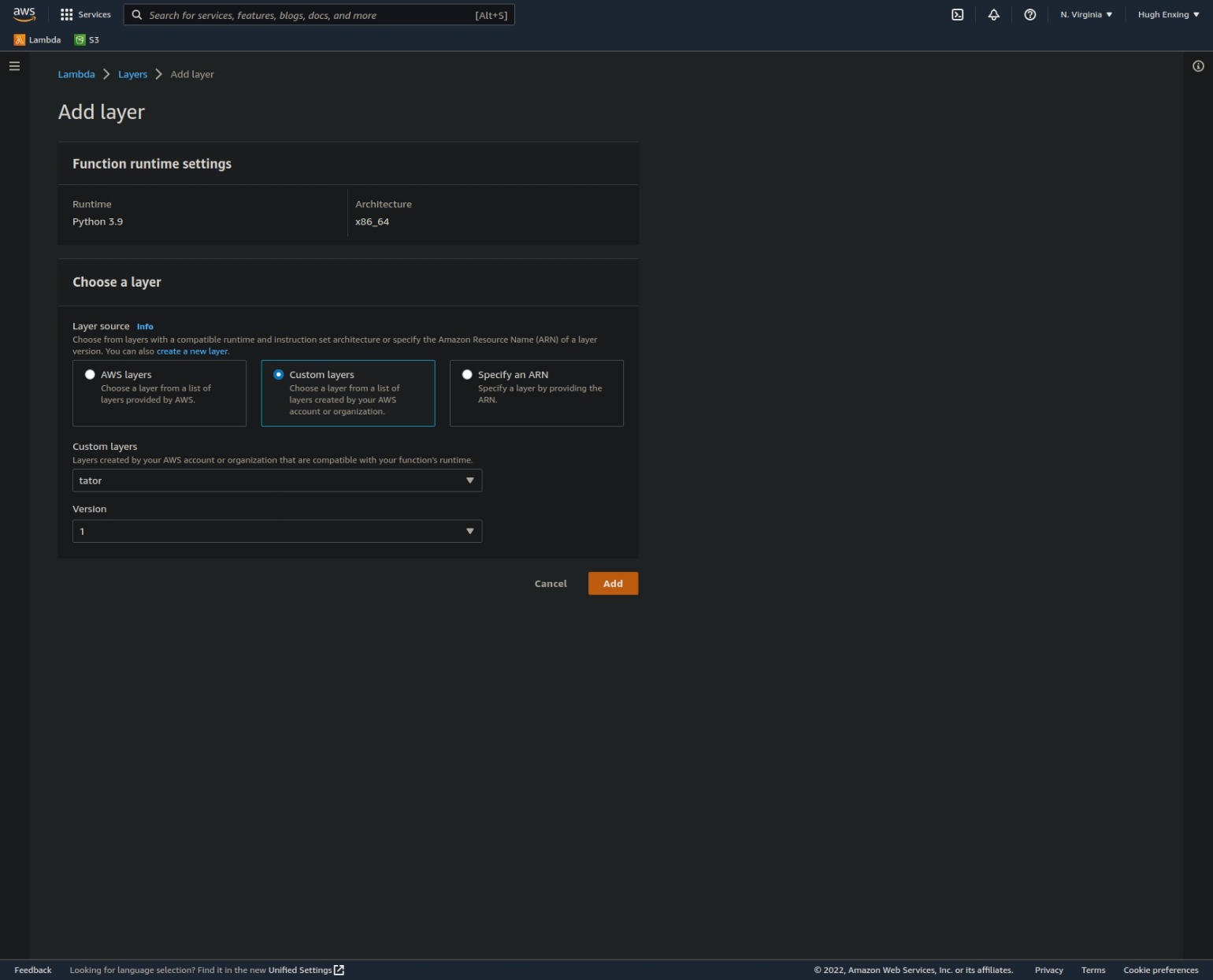
Finally, click the "Add" button.
Next steps
Now that the layer has been added to the Lambda function, you can import tator and use the
tator-py interface to Tator. See the reference documentation for more
information.