Register an algorithm
Tator allows developers to deploy generic algorithm workflows that can be launched on filtered media sets from the web interface. Tator accomplishes this with the help of Argo Workflows, a custom resource definition for Kubernetes for executing scalable containerized workloads. Argo supports many complex workflow architectures, including parallel steps and step dependencies. In this tutorial, we will register the RetinaNet object detector implemented in Detectron2 with pretrained ImageNet weights for batch inference on videos.
Write the algorithm script
Create a file called infer.py and copy the following:
import os
import logging
import tator
import cv2
import torch
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.data import MetadataCatalog
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
# Read environment variables.
host = os.getenv('HOST')
token = os.getenv('TOKEN')
project_id = int(os.getenv('PROJECT_ID'))
media_ids = [int(id_) for id_ in os.getenv('MEDIA_IDS').split(',')]
# Set up the tator API.
api = tator.get_api(host, token)
# Find the localization type for this project.
types = api.get_localization_type_list(project_id)
for box_type in types:
found_label = False
for attribute_type in box_type.attribute_types:
if attribute_type.name == "Label":
logger.info(f"Found attribute type 'Label'!")
found_label = True
if box_type.dtype == "box" and found_label:
logger.info(f"Using box type {box_type.id}!")
break
# Set up detectron model.
logger.info(f"Setting up model...")
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/retinanet_R_50_FPN_3x.yaml"))
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/retinanet_R_50_FPN_3x.yaml")
if torch.cuda.is_available():
logger.info("Found CUDA, using GPU!")
logger.info("Inference will be performed on every frame!")
frames_per_inference = 1
else:
logger.info("CUDA not available, using CPU!")
logger.info("Inference will be perfomed only once per 30 frames!")
cfg.MODEL.DEVICE = 'cpu'
frames_per_inference = 30
predictor = DefaultPredictor(cfg)
class_names = MetadataCatalog.get("coco_2017_train").thing_classes
# Iterate through each video.
for media_id in media_ids:
# Download video.
media = api.get_media(media_id)
logger.info(f"Downloading {media.name}...")
out_path = f"/tmp/{media.name}"
for progress in tator.util.download_media(api, media, out_path):
logger.info(f"Download progress: {progress}%")
# Do inference on each video.
logger.info(f"Doing inference on {media.name}...")
localizations = []
vid = cv2.VideoCapture(out_path)
frame_number = 0
while True:
ret, frame = vid.read()
if not ret:
break
if frame_number % frames_per_inference == 0:
height = frame.shape[0]
width = frame.shape[1]
outputs = predictor(frame)["instances"]
for box, class_ in zip(outputs.pred_boxes, outputs.pred_classes):
# Create a localization spec and add it to list.
spec = {
'type': box_type.id,
'media_id': media.id,
'x': float(box[0] / width),
'y': float(box[1] / height),
'width': float((box[2] - box[0]) / width),
'height': float((box[3] - box[1]) / height),
'frame': frame_number,
'Label': str(class_names[class_]),
}
localizations.append(spec)
frame_number += 1
vid.release()
# Create the localizations in the video.
logger.info(f"Uploading object detections on {media.name}...")
num_created = 0
for response in tator.util.chunked_create(api.create_localization_list,
project_id,
localization_spec=localizations):
num_created += len(response.id)
logger.info(f"Successfully created {num_created} localizations on {media.name}!")
logger.info("-------------------------------------------------")
logger.info(f"Completed inference on {len(media_ids)} files.")
Let's discuss what is happening in this script. First we retrieve information from environment variables that will be mapped from workflow parameters. We construct the API object, and find the localization types corresponding to box dtype and with an attribute called Label. We set up the object detector, handling both CPU and GPU inference (we do only a subset of frames for CPU because it is slower). Then we iterate through each video, and for each we download, do inference, and upload results.
Create a docker image
Next we will define a simple docker image baselined off the PyTorch image from Nvidia. This will allow us to define a very simple Argo workflow that consists of a single step that does everything in the script above. Copy the following into a file called Dockerfile:
FROM nvcr.io/nvidia/pytorch:21.10-py3
RUN python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
RUN python -m pip install tator opencv-python
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
COPY infer.py /infer.py
Then build the dockerfile and push it to DockerHub, or you can push it to a local registry (this is preferable for faster image pulls). If you followed the tutorials to set up your Tator instance, you will have a local registry at localhost:32000 and can build and push the image with these commands:
docker build -f Dockerfile -t localhost:32000/pytorch-tator:latest .
docker push localhost:32000/pytorch-tator:latest
Change the value of localhost:32000 to your DockerHub username if you do not have a local repository set up.
Write the workflow manifest
Create a file called workflow.yaml and copy the following:
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: detectron2-od-
spec:
entrypoint: infer
ttlStrategy:
secondsAfterCompletion: 30
secondsAfterSuccess: 30
secondsAfterFailure: 3600
volumes:
- name: dockersock
hostPath:
path: /var/run/docker.sock
- name: workdir
emptyDir:
medium: Memory
templates:
- name: infer
container:
image: localhost:32000/pytorch-tator
imagePullPolicy: Always
resources:
limits:
cpu: 1000m
memory: 4Gi
env:
- name: PROJECT_ID
value: "{{workflow.parameters.project_id}}"
- name: MEDIA_IDS
value: "{{workflow.parameters.media_ids}}"
- name: HOST
value: "{{workflow.parameters.host}}"
- name: TOKEN
value: "{{workflow.parameters.rest_token}}"
volumeMounts:
- name: workdir
mountPath: /work
command: [python3]
args: [/infer.py]
The workflow is configured to expire after completion within 30 seconds, or to stick around for an hour if the workflow fails (this allows us to inspect logs). We use a RAM disk for scratch space. We request only one CPU core and 4GB of memory; if we are using a GPU we could also request a GPU by adding nvidia.com/gpu: 1. We are mapping the workflow parameters provided by Tator (project_id, media_ids, host, and rest_token) to environment variables so they can be read by the python script.
Set up a project and register the algorithm.
Create a project in Tator using an object detection preset. In the Projects view, click New Project and select the Object Detection preset. Use the project settings view to register the workflow. Under Algorithms in the sidebar, click + Add new.
Set the name and description. The name is what will appear in the context menu for media or sections when launching algorithms. Set Files Per Job to the number of videos you want to input per workflow. This should be a number that is a good balance between the number of files you typically launch on and how many workflows your Argo controller can handle. For this tutorial we will set the value to 1 so that there is one workflow launched per video. Upload the workflow.yaml to the Manifest field.
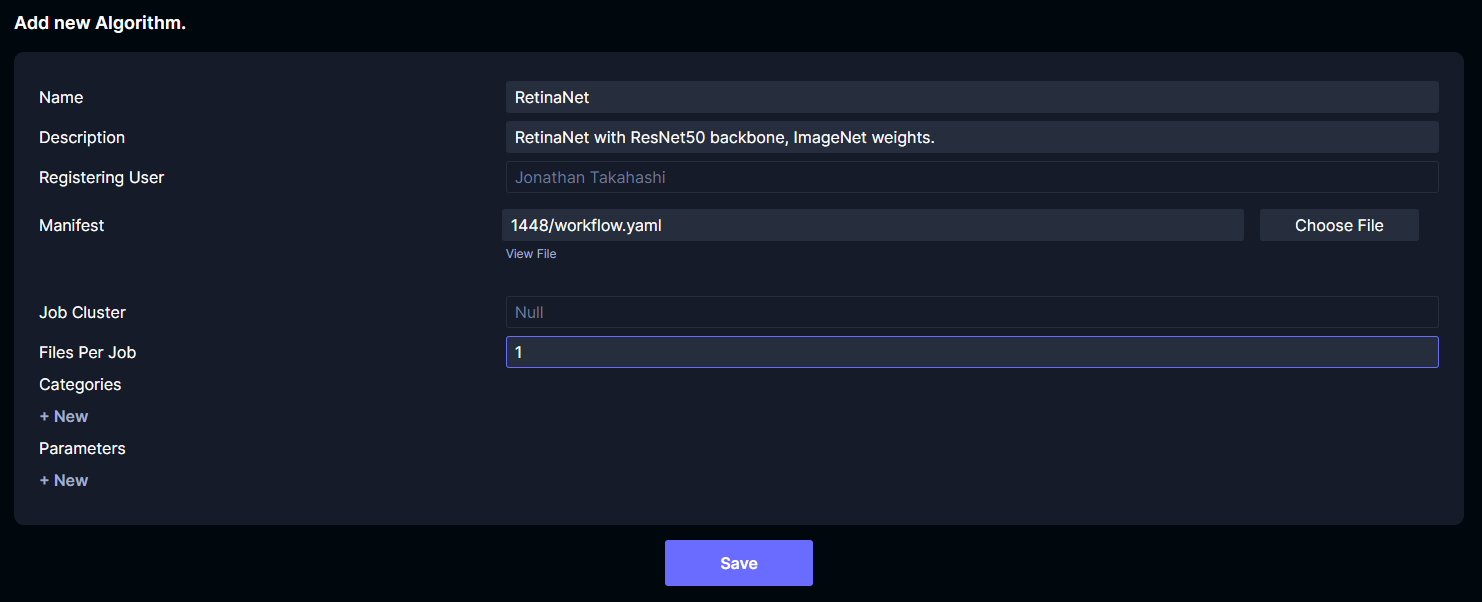
Click Save.
Launch the algorithm
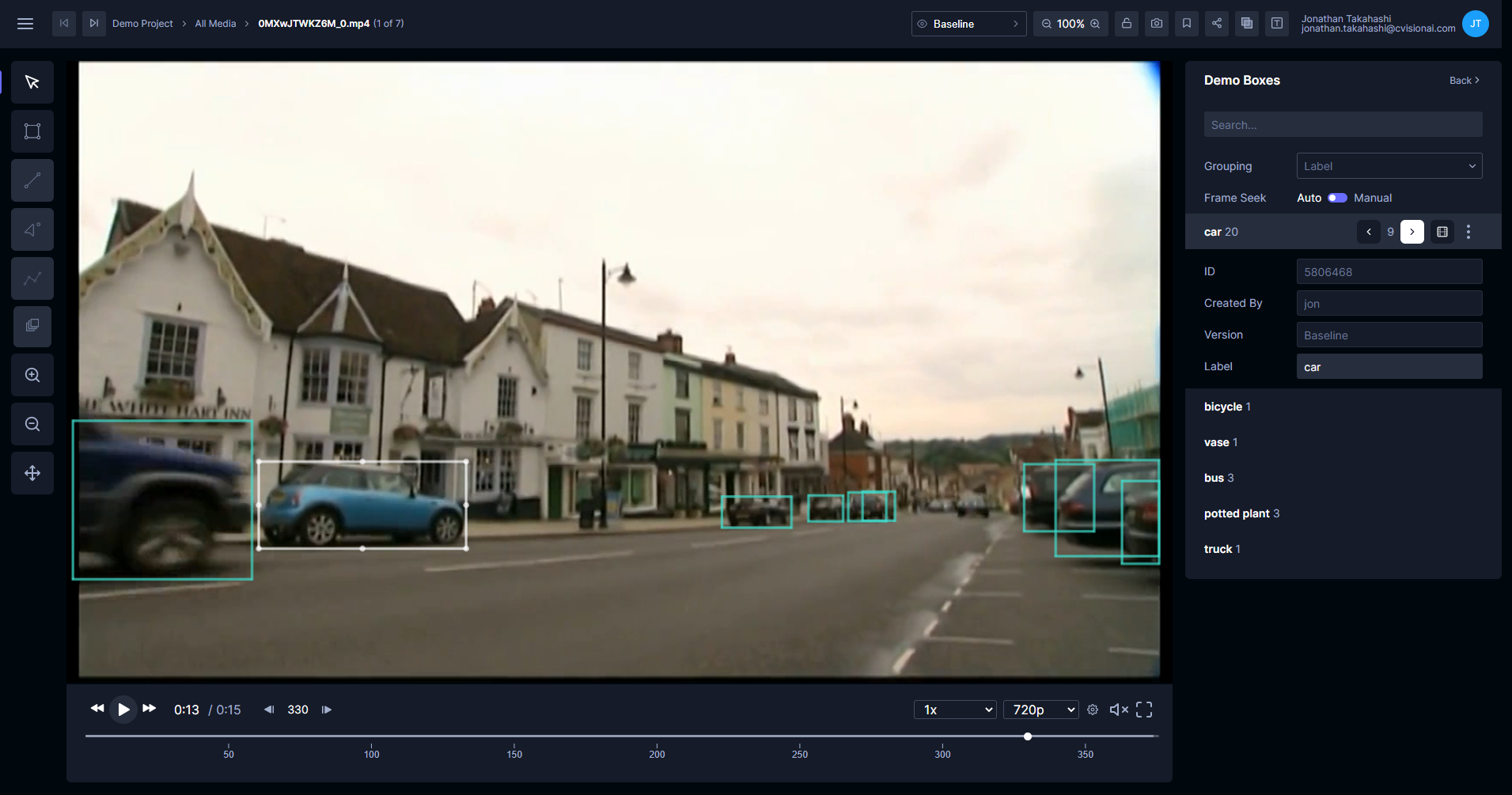
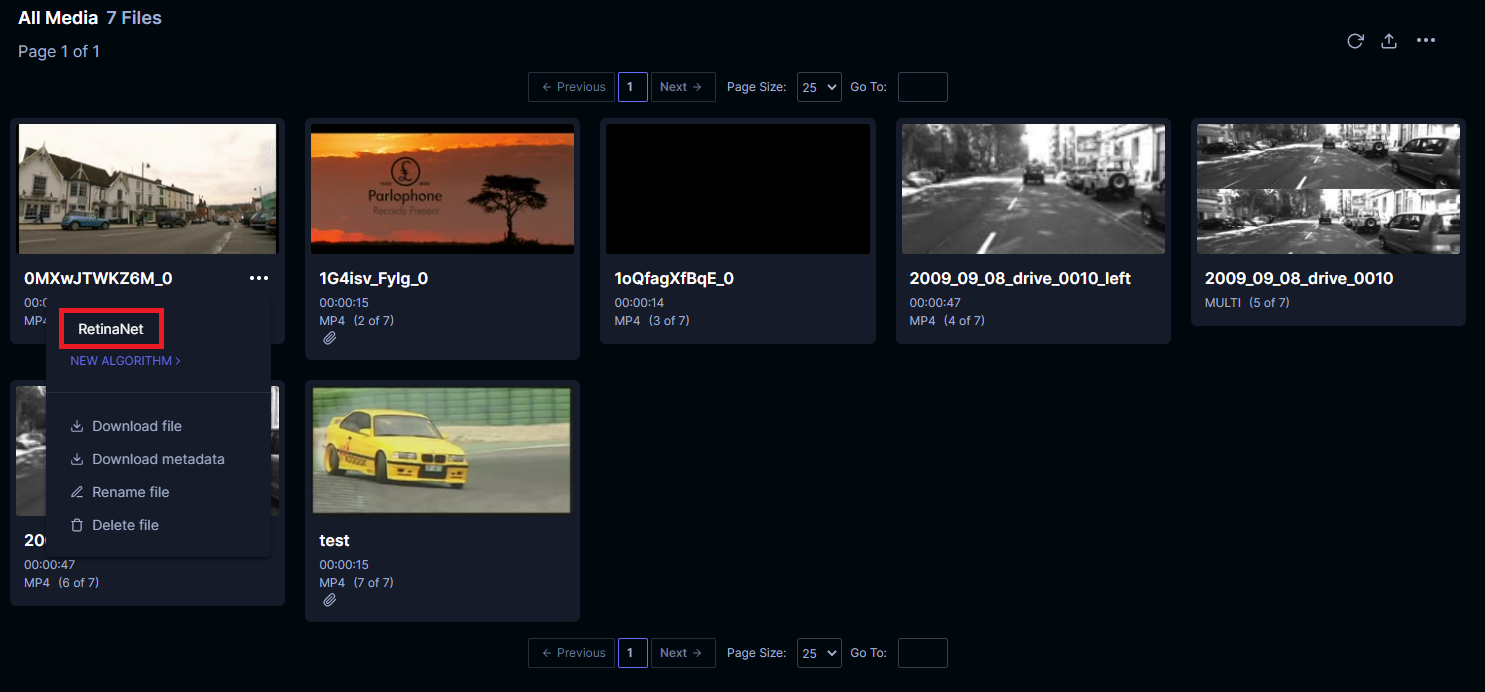
In the project detail view, click a context menu under a media card or in a section and select the algorithm you registered.
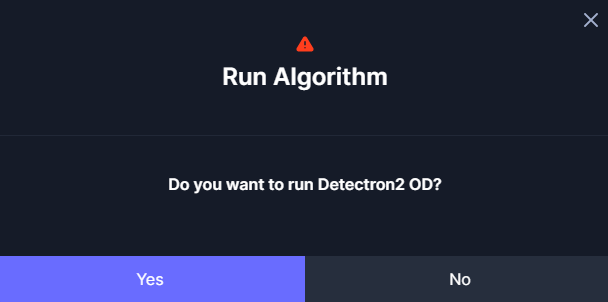
You will see a confirmation dialog. Click Yes.
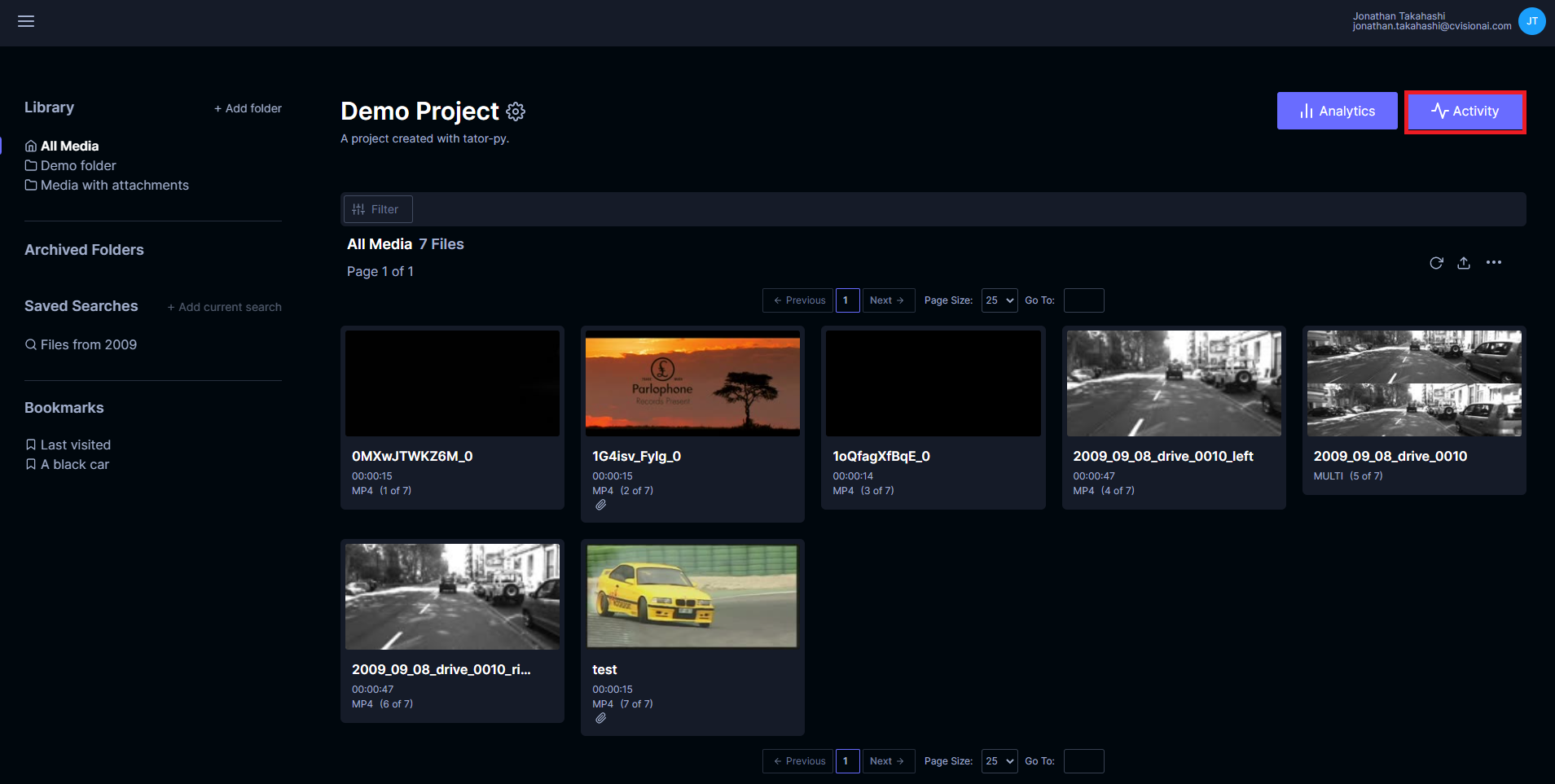
A notification will display. Click Close. Click on the Activity button.
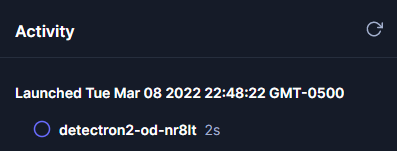
This will display a single workflow in progress. You can expand it to see each individual step's status, but we only have one step in our workflow.
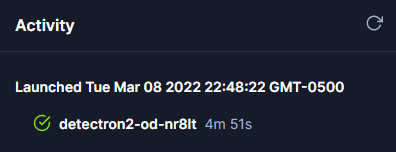
The workflow will take some time to complete, especially if it is executing using CPU only. Workflow speed can be improved using GPUs and batch inference. Once it is complete, the status will be displayed with a green check mark.
Now you can open the media where inference was performed. If CPU was used, inference was performed on only every 30 frames.